Way back in the mists of time (ie, 2006), jules and I saw what was going on with people estimating climate sensitivity, and in particular how this literature was interpreted by the authors of the IPCC AR4. And we didn’t like it. We thought that any reasonable synthesis should consider the multiple lines of evidence in a coherent fashion in order to form a credible overall view. This resulted in the paper “Using multiple observationally‐based constraints to estimate climate sensitivity” described in this blog post (paper here), which people unfamiliar with the story might like to glance at before progressing further…
It’s fair to say that our intervention was not met by universal approval at the time, with the established researchers mostly finding excuses as to why our result might not be entirely trustworthy. Fine, do your own calculations, we said. And they didn’t.
Time passed, and a new generation of people with different backgrounds became interested in estimating climate sensitivity. The World Climate Research Program (WCRP) made it a central theme in one of their Grand Challenges in climate science. There were a couple of meetings in Ringberg that jules and then I attended sequentially.
In 2016, several of leaders of this WCRP steering group wrote a paper which kicked off a project to perform a new synthesis of the evidence on climate sensitivity. Their idea was to form an overall synthesis of the multiple lines of evidence, roughly along the lines that we had originally proposed, but in a far more comprehensive and thorough fashion. This is something that the IPCC isn’t really equipped to do, as it just assesses and summarises the literature. The project leaders considered three main strands of evidence: that arising from process studies (ie the behaviour of clouds, including simulations from GCMs), the transient warming over the historical record, and paleoclimate. Jules was one of the lead authors for the paleo chapter, but I wasn’t involved at the outset. However when invited to join the group I was of course happy to contribute to it, having thought about the problem off and on for the past decade.
Writing it was a lengthy and at times frustrating process, due to the huge range of ideas, topics, backgrounds and knowledge of the author team. That is also what gives this review its strength, of course, as we have genuine experts in multiple areas of modelling and data analysis, covering a huge range of time scales and techniques, and the different perspectives meant we gave each other quite a workout in testing the robustness of our approaches and ideas. During the 4 year process we had regular videoconferences, typically 9pm UK time, being 6am for Japan, 10am in Australia and afternoon for the continental USA. Luckily we had an 8-9h gap in the global spread so no-one actually had to get up in the middle of the night each time! We also had a single major writing meeting in Edinburgh in summer 2018 which almost all the main authors were able to attend in person, and a handful of “meet-ups of opportunity” when subsets happened to go to other conferences. In all, it was good practice for the new normal that we are enjoying due to COVID.
The peer review was probably the most extensive I’ve experienced, with something like 10 sets of comments – this was something we were all keen on, as we suspected it would be beyond the compass of just the usual 2-3 people. Comments were basically encouraging but gave us quite a lot to work on and in face we reorganised the paper substantially for the better resulting in the 2nd set of reviews being very positive. Finally got it done a couple of months ago and it was accepted subject to very minor corrections (which were mostly things we had spotted ourselves, in fact).
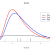
The new paper has now been published, actually I’m not entirely sure it is up yet (minor snafu on the embargo timing) but anyone who needs an urgent look can find it here. I may write more on the details if pressed, but for now here is a quick peek at the main results:

The “baseline” calculation is what we get from putting together all the evidence, with a resulting 2.6-3.9C “likely” range. The coloured curves are various sensitivity tests, with the purple line at the top defined as the range from the lowest 17th percentile, and the highest 83rd percentile, across these tests. This isn’t really a probability range and doesn’t correspond to any particular calculation.

That’s interesting – has your view changed at all since 2013 ? http://julesandjames.blogspot.com/2013/02/a-sensitive-matter.html?showComment=1359776188980#c4055746020692259831
Pingback: Climate sensitivity – narrowing the range | …and Then There's Physics
I think it’s changed a bit – nothing to specifically contradict that post, but there is more evidence against low values (2.5 or lower) now that we understand the nonlinearity/state dependence a bit better. Basically, the modest warming (compared to forcing) that we have seen over the past century is no longer such a clear pointer to low sensitivity. 3C is still looking pretty close though.
Pingback: Science breakthrough of the year (runner-up) | BlueSkiesResearch.org.uk