Guayas is a region in Ecuador that has had a particularly tough time with COVID-19. Prompted by this Twitter post from Karsten Haustein I have done a bit of modelling…
Spot on. (Un)fortunately, we have a real-world example. Corresponds to ~300.000 deaths in 6 weeks in the UK. pic.twitter.com/Ruei6U0w1c
— Karsten Haustein 🌍 (@khaustein) May 9, 2020
The daily death totals are available from here from where I could also work out that the typical background mortality was about 60 per day. They hit a peak of over 700(!) and the total excess deaths looks like about 12k in a few weeks (out of 4.5 million, that’s over 0.25%). So that in itself puts a lower bound of that magnitude on the “infection fatality rate” or IFR in that region. (I think Karsten’s number on the tweet could be open to misinterpretation, the excess being half their annual mortality is true enough, but they are a young growing region so it’s a lower percentage of total population than 300k would be in the UK.)
But maybe modelling could shed a little more light?
It was a bit of a challenge to get the model to work well on this data set and I had to tweak it a bit. Most importantly, the time to death distribution in the model seems too broad and flat. I had to sharpen it significantly to be able to reproduce the peak. This seems intuitively reasonable as I’m sure they didn’t have thousands of people kept alive on banks of ventilators, but on the other hand I have no rigorous basis for this modification so the post is a bit handwavy. I think it’s reasonable but different choices might have resulted in different results. I also changed the way I am handling model error a bit as I wanted to really explore how well I could fit the data. There was a bit of tweaking involved to make it work ok. My aim was to see if I could fit the data with a range of different IFR values, and perhaps infer what values might be compatible with the data.
Without further ado, some results. I fixed the IFR at various different values as shown (just by using a really narrow prior centred on those values).




Using 0.2%, it’s a horrible fit that massively underestimates the peak. Not surprising really, given that 0.27% of the whole population died. In fact despite the tight prior, it refuses to stick at that value and drifts up to 0.21%. Even the simulation with 0.3% is not great. The logarithmic scale of the plot flatters it a bit, and it stays comfortably under the peak for quite some time. Interestingly, Rt is estimated to be significantly over 1 during the declines here (despite the attempt at control), because the herd immunity is sufficiently high to play a significant role in squashing the epidemic. IFR=0.4% gives an entirely satisfactory simulation, indistinguishable from the IFR=1% case (at which herd immunity ceases to be a significant factor). The only tell-tale difference is in the Rt values obtained. I suspect that the 0.5 value on the 1% plot is a bit optimistic, we haven’t managed that anywhere in Europe despite being much richer and not having been completely overwhelmed by the epidemic to anything like the same extent. On the other hand we all did better than Rt=0.94.
Splitting the difference, IFR =0.7% is visually indistinguishable again, with Rt = 0.58 being a bit less optimistic than the 1% run. This value (well, 0.75%) is what I’ve been using in all of my modelling.
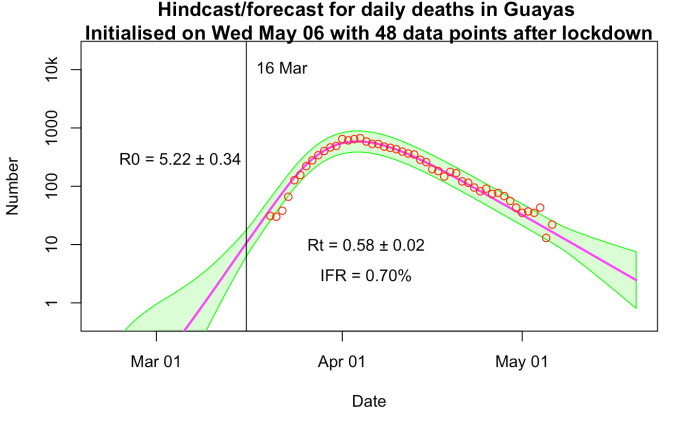
Ecuador is a very young country compared to the UK (which would point to a lower IFR) but also much poorer and obviously healthcare was completely overwhelmed with this epidemic (which would point to a higher one). Do these factors cancel, compared to the UK? I have no idea, but I would think that epidemiological modellers might be able to draw more concrete conclusions than I am prepared to do.
If I could find daily data from Bergamo, Italy, I could play the same game there. Lombardy as a whole is only at the 0.14% fatality level which I think won’t be enough to be useful in the same way.



So (because I’ve been confused by this before)… all else being equal, a higher IFR (1% compared to 0.4% say) implies a smaller number of infected-and-recovered, hence less herd immunity, and hence gives a lower Rt?
Yes, because I’m working backwards from a fixed number of deaths, a big IFR means there have been fewer cases – and hence the only way to get the decline is through small Rt. Whereas if the IFR is small, we already have lots of cases (maybe past herd immunity even), so you don’t want such a small Rt to push it down. R (in the model) relates to how many people would be infected, if they were all susceptible, not directly to the actual number that do get infected.
However, just to complicate things, I believe that many statistical estimates ignore this factor and just base their estimation on the rise/fall in cases or deaths. Which is ok when the epidemic is small. And is also ok even with a big epidemic if all you want to do is extrapolate a week or two under the same assumption. But if you want to know what R actually is, it may give completely the wrong answer.
James –
> Not surprising really, given that 0.27% of the whole population died.
Is that right? Is that a number for all cause mortality?
My bad. Didn’t read carefully – I see that you meant just for that region, not all of Ecuador
You have rejected IFR = 1 due to lower than you expect Rt of 0.5.
Suppose there was a population that grew most of it’s food, stored it at home, and mostly could avoid going anyone for any reason for months at a time. Might Rt approach 0.0 fairly closely?
Now, I don’t understand the economics and social structure of Guayas. So I have a question that we might ask instead.
What IFR gives the best least mean squares fit to the data?
My eye says more than 1.0, yet my eye might well be wrong.
Opps. Please change “going” to “meeting with”.
Thinking a bit more, that isn’t a proper Bayesian way to ask the question. Would you try a much broader prior please?
Phil, the 0.4% run and the 1% run are really indistinguishable. Any value greater than 1% is also indistinguishable, it just implies a smaller epidemic in terms of total infected number (which I have no constrain on other than by inverting the number of deaths). And all higher values also result in an estimate of Rt =0.5, it is only in the small-IFR cases where the epidemic is large enough for the herd immunity effect to be noticeable that the runs differ. There’s a (1-x/N) term in the equations, where x is total (infected+immune) and N is total population, if this is greater than about 0.95 it might as well be 1 for all the difference it makes.
If people could really isolate fully in their houses…they still have families which could give a week or two of spread…but after that R should drop to zero pretty quickly. But people can’t (won’t) all isolate to such an extent.
Thanks for the answer. The center line is closer to the dots at the right side of the plot for 1% compared with 0.4% is what my eye says. Peak looks closer as well. The difference might not be real, or significant.
So would it be fair to say that your modeling excludes low IFRs (0.4% and below)? And doesn’t say much about higher IFRs? (1% and above)